
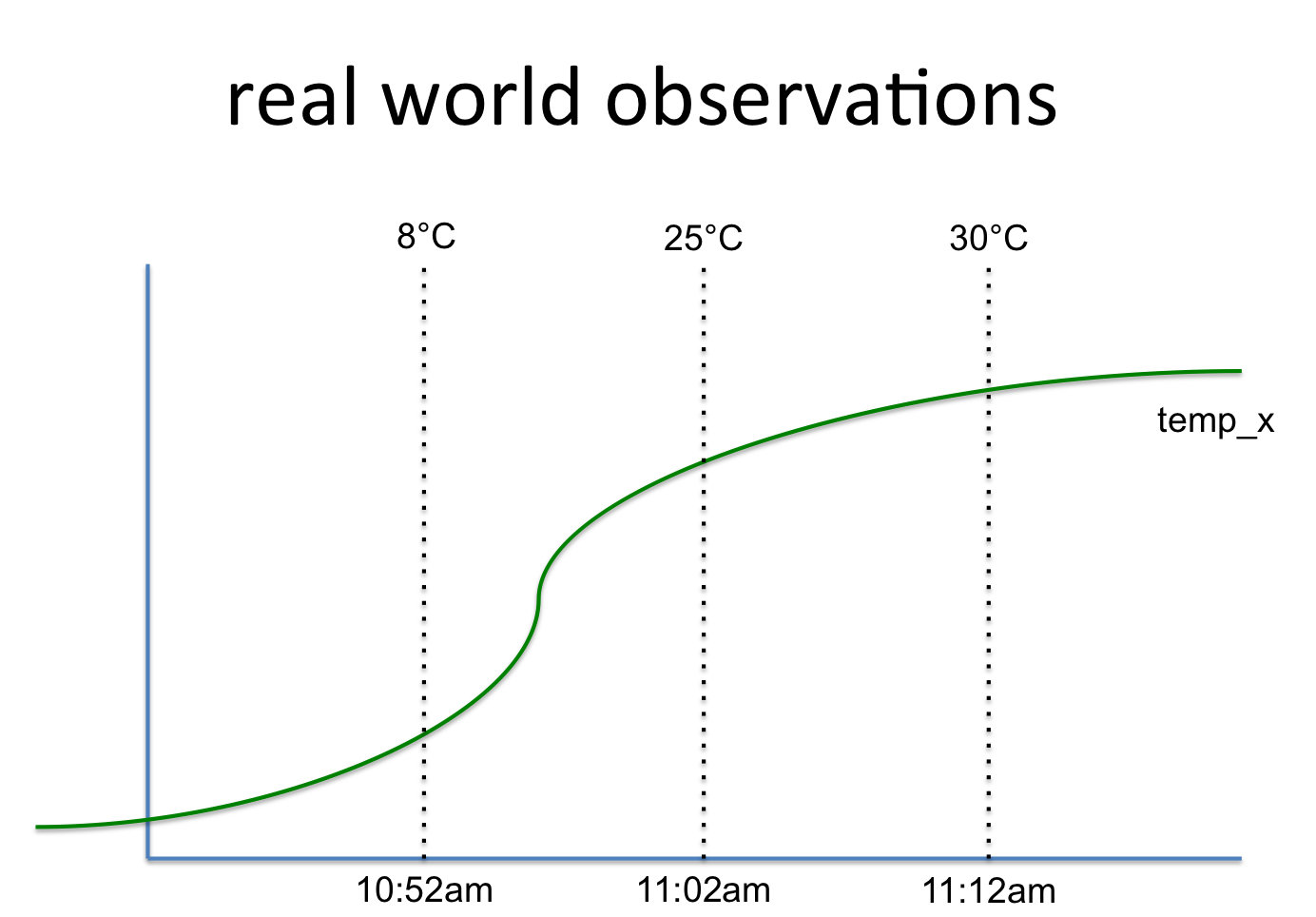
想象一下,您正在从一个CSV文件中读取数百万个数据行。每行显示传感器名称、当前传感器值和观察该值的时间戳。
key, value, timestamp
temp_x, 8°C, 10:52am
temp_x, 25°C, 11:02am
temp_x, 30°C, 11:12am
这与这样的信号有关:
所以我想知道将其存储到Apache HadoopHDFS中的最佳和最有效的方法是什么。第一个想法是使用BigTable又名HBase。这里的信号名称是行键,而值是随时间保存值的列组。可以向该行键添加更多列组(例如统计信息)。

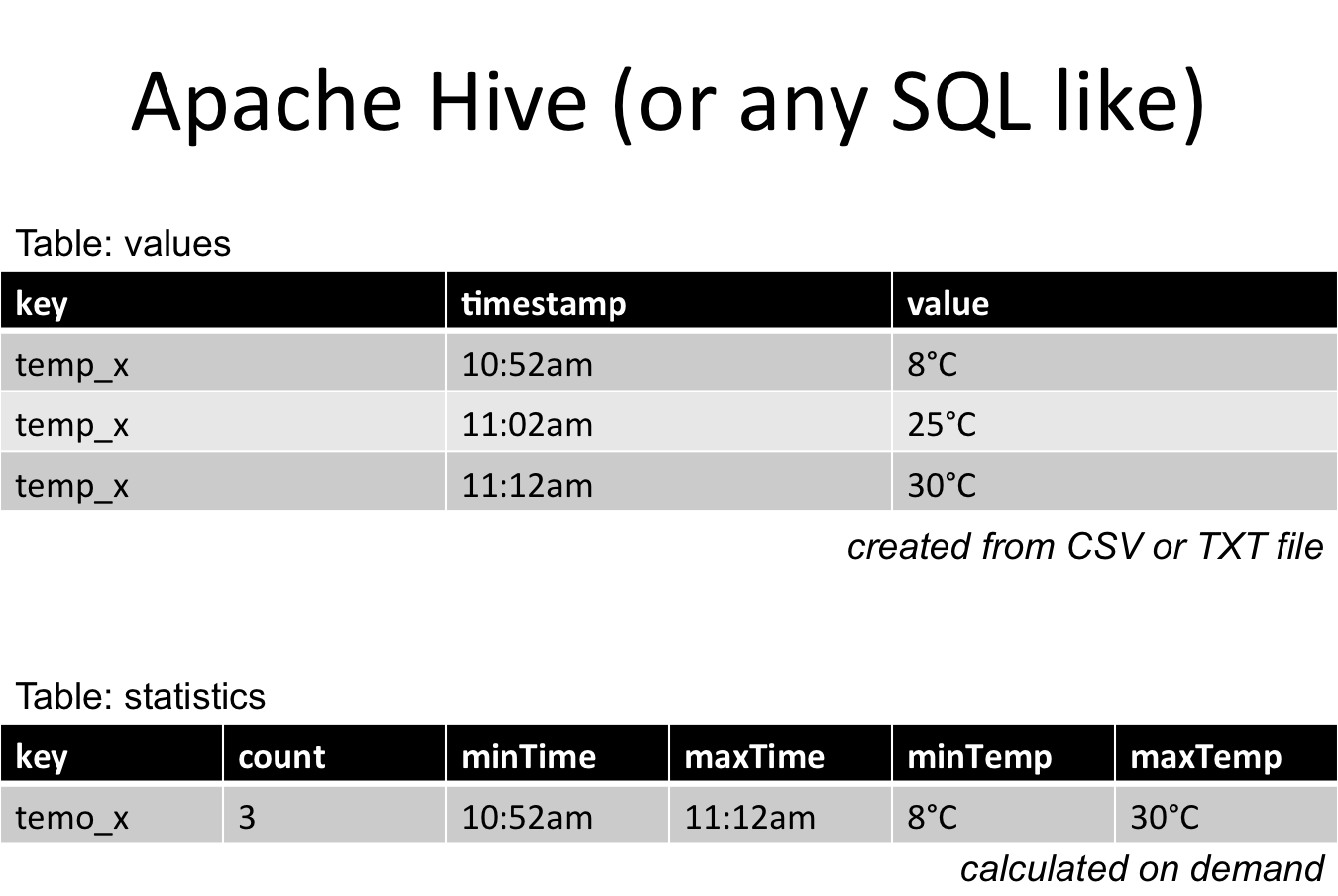
另一个想法是使用表格(或类似SQL)结构。但是你在每一行中复制键。你必须按需计算统计数据并将它们分开存储(这里是第二个表)。
我想知道是否有更好的主意。存储后,我想在Python/PySpark中读取数据并进行数据分析和机器学习。因此,数据应该可以使用模式(SparkRDD)轻松访问。
我会考虑使用。
>
写入qarque文件(节省空间和时间)
从镶木地板文件加载数据
